The client is a SaaS company based in the US, focused on workforce management solutions. They had a solid product and a growing customer base.
As more customers joined and the platform got more complex, the old release process and infrastructure simply couldn’t keep up.
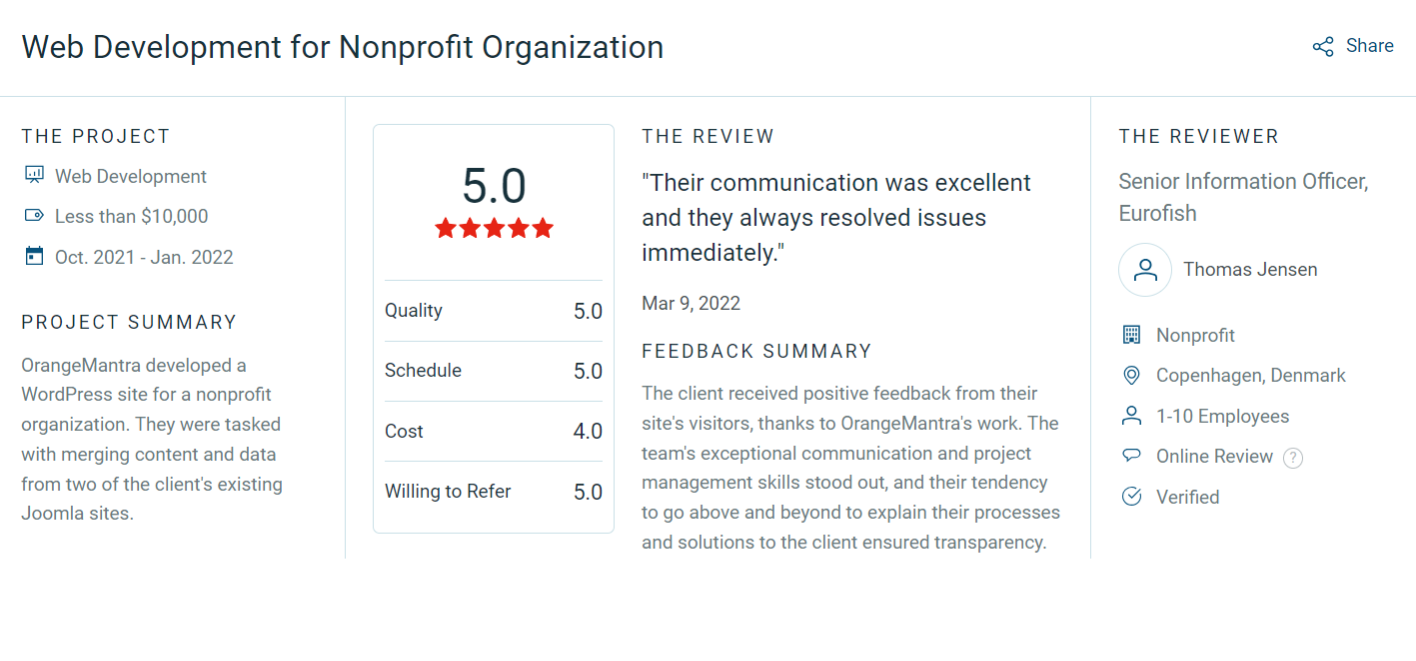
The business was at that stage where growth wasn’t the problem. The real challenge was building a strong enough technical foundation to support the growth without burning out the team or disappointing customers.
SAAS
Releases took anywhere from 3 to 5 hours, and even then, no one felt confident pressing the deploy button. A senior engineer had to be available, and the whole team pretty much held their breath until it was over.
Their application was built as one large monolithic service. It worked in the early days, but now every small change risked breaking something unexpected. Developers were spending more time testing and debugging than actually shipping features.
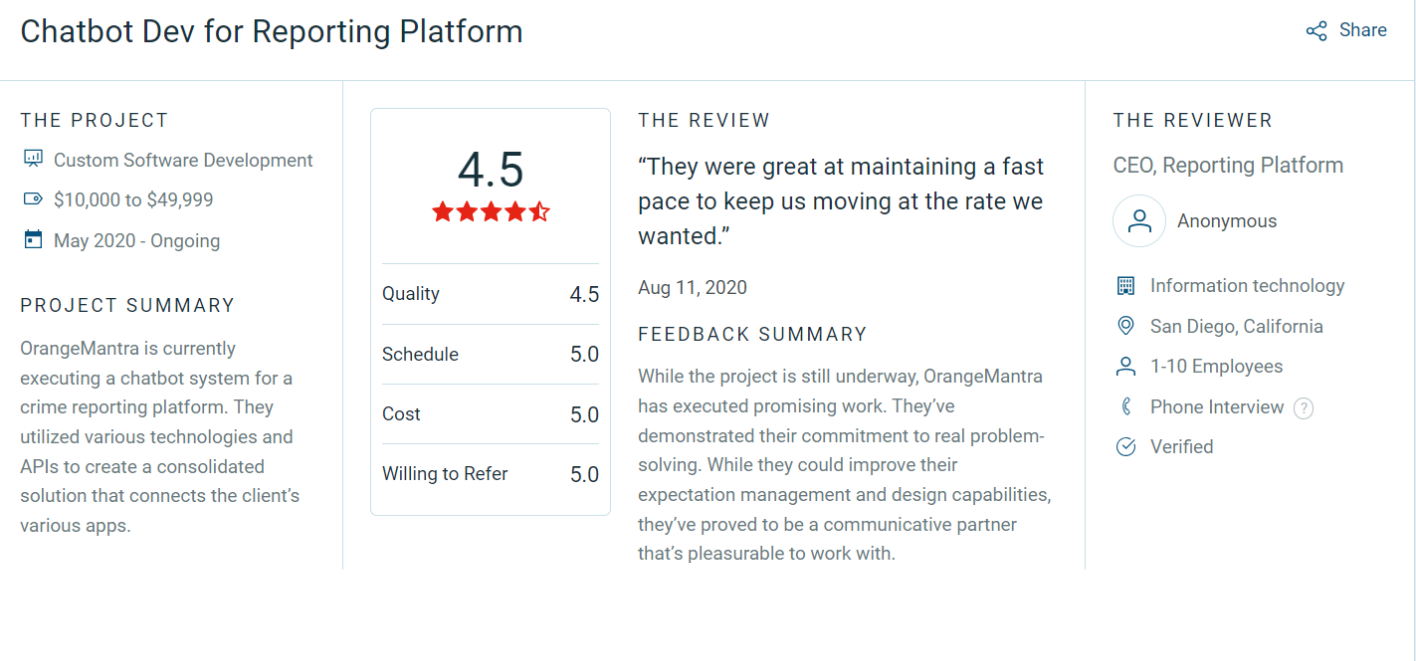
Because the system lacked proper monitoring and logging, issues often surfaced only after customers complained. Each outage turned into guesswork. Fixing production problems felt more like detective work than engineering.
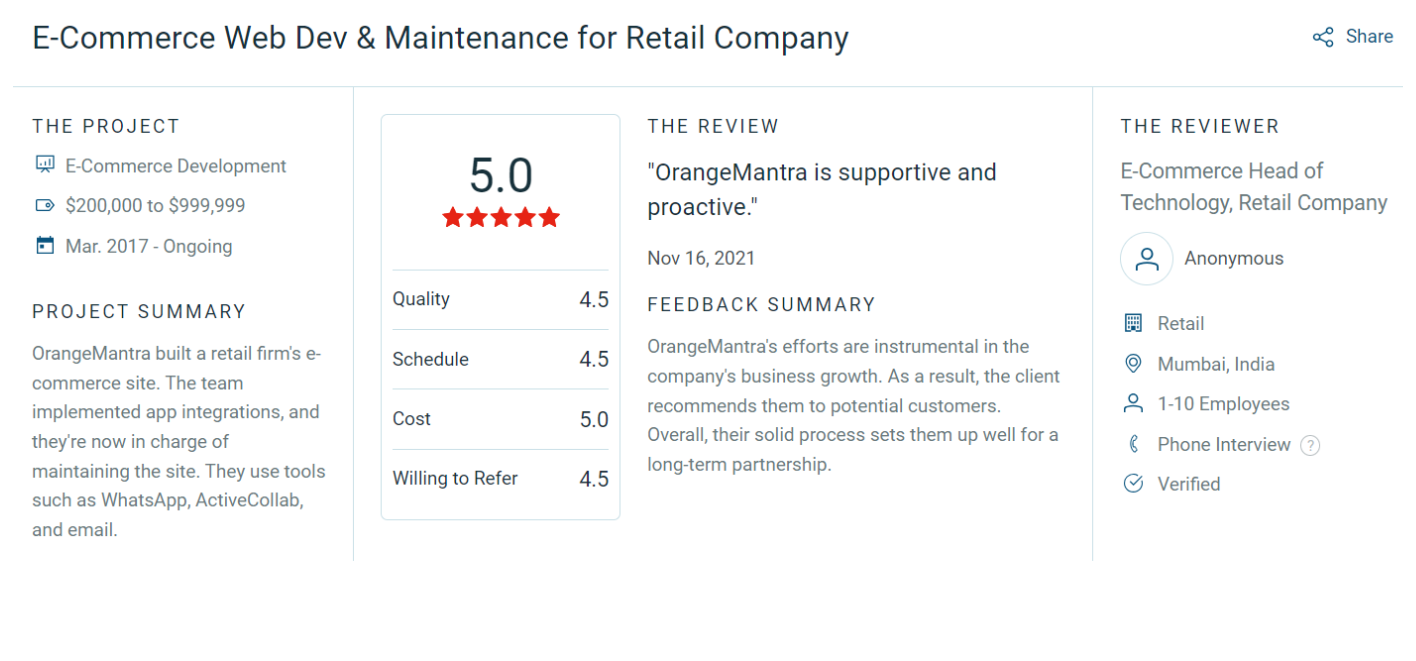
Their AWS setup wasn’t optimized. Oversized instances, unused resources running 24/7, and no autoscaling meant they were paying more than they should without getting the reliability they needed.
We started with a simple question: “What does stability and speed actually look like for this team?” Because DevOps is ultimately about how confidently a team ships, how predictably their system behaves, and how sustainably the business can scale.

We replaced their manual release process with a fully automated GitHub Actions pipeline. Builds, tests, scans, and deployments now run consistently across all environments.
Tools used: GitHub Actions, ArgoCD, SonarQube, Snyk, Slack


We containerized the application using clean, versioned Docker images and moved everything to EKS. Kubernetes handled scaling, rollouts, and self-healing, which drastically improved uptime and deployment flexibility.
Covered: Docker packaging, EKS setup, autoscaling, blue-green deployments
We rebuilt their AWS infrastructure using Terraform modules so every environment could be reproduced on demand. This eliminated configuration drift and made infrastructure changes reviewable and version-controlled.
Covered: VPCs, IAM, EKS, RDS, S3, networking


Security checks were integrated directly into CI, and secrets moved to AWS Secrets Manager. IAM roles were cleaned up to enforce least privilege and reduce exposure.
Covered: Scanning, secrets handling, IAM hardening
By the end of the engagement, the difference in how the team shipped, monitored, and scaled their platform was visible in every part of the engineering workflow.

Release cycles went from weekly to multiple safe deployments per day. Automated pipelines cut release time by nearly 65 percent, and rollback confidence meant developers weren’t afraid to ship frequent changes.
With Kubernetes handling restarts and autoscaling, the platform started behaving predictably even during traffic spikes. Uptime improved to 99.9 percent, and incidents caused by bad deployments almost disappeared.
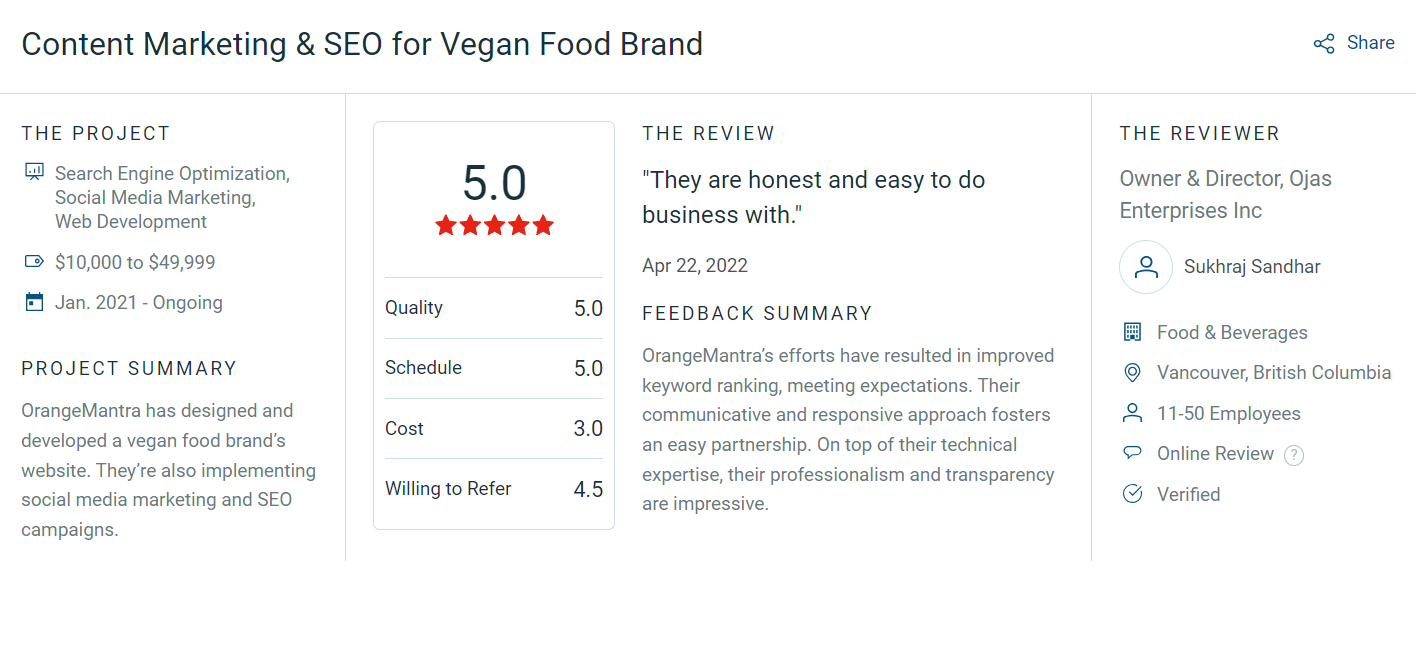
Optimizing compute, right-sizing resources, and removing unused assets led to a 25 to 30 percent reduction in AWS bills. The best part: performance improved even while spending less.
For this client, DevOps changed how their entire engineering team shipped, scaled, and supported the product. With automation in place, cleaner infrastructure, real observability, and a security-first mindset, the team finally had the stability they needed to grow without slowing down.
If you’re facing similar challenges or want to understand what a structured DevOps transformation could look like for your team, we’re always open to a conversation.