
Don't let fragmented, slow, or unreliable data hold your business back. With our custom ETL development services, you can integrate, transform, and load data at scale with precision, speed, and intelligence built in.





Not sure where to start your data integration journey? Our ETL consulting services help you assess your current data landscape, identify bottlenecks, and build a scalable pipeline roadmap before a single line of code is written.
We design and build custom ETL pipelines from the ground up — tailored to your data sources, transformation logic, and target systems. From structured databases to unstructured data lakes, we handle the full lifecycle.
As a specialist in AI-ML ETL development services, we layer artificial intelligence and machine learning into your data pipelines to enable smarter data processing, anomaly detection, and predictive data quality management.
Move your ETL workloads to the cloud with architecture built for elastic scale, cost efficiency, and high availability. We design cloud-native pipelines on AWS, Azure, and GCP that grow with your data.
Business decisions can't wait for overnight batch jobs. We build real-time streaming ETL pipelines using Apache Kafka, Spark Streaming, and Flink to deliver live data insights as events happen
Unreliable data produces unreliable decisions. We build data quality frameworks and governance layers into your ETL pipelines to ensure every record that enters your warehouse is clean, consistent, and compliant.
Power your business intelligence tools with reliable, structured, and business-ready data. We design ETL workflows optimized for BI platforms like Power BI, Tableau, Looker, and more.
Legacy ETL tools slowing you down? We help you migrate from outdated platforms like Informatica, SSIS, or Oracle Data Integrator to modern, cloud-native alternatives — with minimal disruption and zero data loss.
ETL pipelines need constant care. Our managed ETL services provide proactive monitoring, performance tuning, failure alerts, and ongoing enhancements, so your data never stops flowing.
We have built a dedicated portal for a large-scale infrastructure provider to automate approval workflows for field operations covering tower foundations, earth wire installations, and more while enabling secure offline data storage on mobile devices. The solution automatically synced the data that was captured to the server as soon as the network connection was restored. This eliminated delays that occurred in the absence of network access. Automated workflows significantly reduced approval of bottlenecks, improving project timelines, while a dynamic form structure allowed real-time updates to meet evolving regulatory and operational needs.

Orangemantra used a staff augmentation model to develop a cutting-edge solar monitoring app and portal for a leading renewable energy provider managing a growing number of solar installations. The platform features real-time alarm prioritization, fault detection, asset catalog management, and an integrated ticketing module built through agile, iterative development. The result was a significant reduction in downtime through rapid fault responses, smarter data-driven decisions via a comprehensive performance dashboard and streamlined maintenance workflows with improved team coordination and transparency.

Orangemantra developed a user-friendly WordPress website for Live. Well, a home care provider serving senior citizens is aimed at acting as a resource hub for elderly individuals and their caregivers. The design emphasized large, easy-to-read fonts; high color contrast; simple navigation; and a clutter-free layout to reduce cognitive load, fully responsive across tablets and smartphones. The website earned positive feedback for its accessibility and became a central community platform, with the client continuing to partner with OrangeMantra for ongoing maintenance and engagement.

Data problems don't fix themselves. At Orange Mantra, we map every ETL solution directly to the business challenge it resolves. Here's how our adaptive ETL development services turn complex data pains into measurable outcomes.
Unified Data Integration — Connect every source, database, API, and cloud platform into a single, coherent data flow.
Data Cleansing Pipelines — Automated validation, deduplication, and standardization ensure every record is trustworthy before it reaches your BI layer.
Optimized ETL Pipelines — Parallelized extraction, incremental loading, and in-memory processing deliver dashboards that refresh in minutes, not hours.
Cloud-Native Architecture — Elastic, serverless ETL infrastructure that scales automatically with your data volume and user demands.
Automated ETL Workflows — End-to-end pipeline automation eliminates human intervention, reduces errors, and frees your team for higher-value work.
Audit-Ready Data Pipelines — Built-in data lineage, access controls, and compliance-first design for GDPR, HIPAA, and SOC 2.
Streaming ETL Solutions — Apache Kafka and Spark Streaming pipelines that deliver live data for time-critical business decisions.
Modernized Data Architecture — Migrate from outdated ETL tools to cloud-native, API-first pipelines without disrupting operations.
Self-Healing Pipelines — Intelligent monitoring and automated recovery reduce downtime and the engineering overhead of keeping pipelines healthy.
High-volume batch jobs that move and transform large datasets on a defined schedule with maximum throughput.
Event-driven pipelines for sub-second data delivery using Kafka, Flink, and Spark Streaming.
Star/snowflake schema design and dimensional modeling for BI-optimized data warehouses.
Managed cloud-native pipelines using Glue, ADF, Dataflow, and Databricks for elastic, cost-efficient ETL.
Machine learning enhanced data processing for intelligent cleansing, classification, and anomaly detection.
Automated validation, lineage tracking, and compliance-driven controls baked into every pipeline.
Modern ELT approaches with dbt for cloud warehouse-native transformation at scale.
Connecting third-party platforms (Salesforce, SAP, Shopify) into your data ecosystem via REST, GraphQL, and webhooks.
Workflow management using Apache Airflow, Prefect, and Dagster to schedule, monitor, and manage complex pipeline dependencies.
 Apache Spark
Apache Spark AWS Glue
AWS Glue Azure Data Factory
Azure Data Factory Talend
Talend Informatica
Informatica dbt
dbt SSIS
SSIS Apache Kafka
Apache Kafka Apache FlinkSpark Streaming
Apache FlinkSpark Streaming AWS Kinesis
AWS Kinesis Google Pub/Sub
Google Pub/Sub Azure Event Hubs
Azure Event Hubs Snowflake
Snowflake Amazon Redshift
Amazon Redshift Google BigQuery
Google BigQuery Azure
Azure Synapse Analytics
Synapse Analytics Databricks
Databricks Apache Airflow
Apache Airflow Prefect
Prefect Dagster
Dagster Luigi
Luigi AWS Step Functions
AWS Step Functions Azure Logic Apps
Azure Logic Apps Python (Pandas, Scikit-learn, PyTorch)
Python (Pandas, Scikit-learn, PyTorch) MLflow
MLflow Azure ML
Azure ML Google Vertex AI
Google Vertex AI Great Expectations
Great Expectations Apache Atlas
Apache Atlas Collibra, Atlandbt Tests
Collibra, Atlandbt Tests AWS Lake Formation
AWS Lake Formation Power BI
Power BI Tableau
Tableau Looker
Looker Superset
Superset Grafana
Grafana Metabase
MetabaseThe right talent makes the difference between a pipeline that runs and a pipeline that performs. At orangemantra, you can hire domain-specific ETL specialists who have built high-impact data solutions across industries.
Apache Spark, Kafka, Airflow, dbt, AWS Glue, Azure Data Factory, Python
Custom ETL pipelines, data warehouse loading, real-time streaming, migration projects
Enterprise data modeling, cloud warehouse design, governance frameworks, schema design
Data strategy, lake/warehouse architecture, ETL platform selection, compliance design
AI-ML ETL development services, Python ML libraries, SageMaker, anomaly detection, feature pipelines.
Intelligent cleansing, AI-enhanced transformation, predictive pipeline monitoring.
Developing custom ETL pipelines could be overwhelming — but with our structured, step-by-step methodology, we remove the complexity and deliver reliable, scalable solutions on time.

We audit your existing data landscape — sources, formats, volumes, quality, and pipeline maturity — and identify integration gaps, bottlenecks, and quick wins.

We design a pipeline architecture tailored to your data volume, latency requirements, cloud environment, and budget — selecting the best tools and frameworks for your specific use case.

Our engineers build extraction connectors, define transformation logic, design target schemas, and develop quality validation layers — with version-controlled, production-grade code throughout.

Testing, Validation & UAT We run comprehensive data validation, reconciliation checks, performance testing, and parallel run comparisons to ensure the pipeline delivers accurate, complete, and timely data before go-live.

Post-deployment, we configure monitoring dashboards, alerting systems, and automated recovery workflows. We continuously tune pipeline performance and adapt to schema or volume changes as your business evolves.

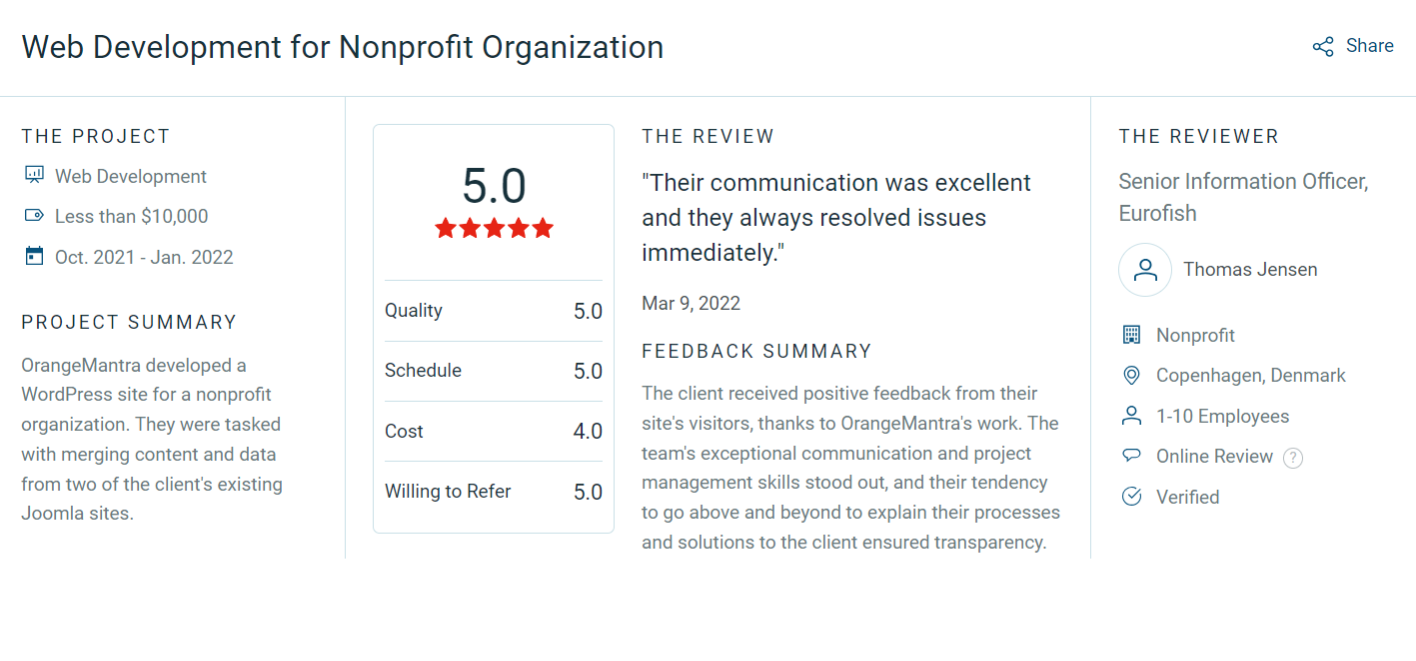
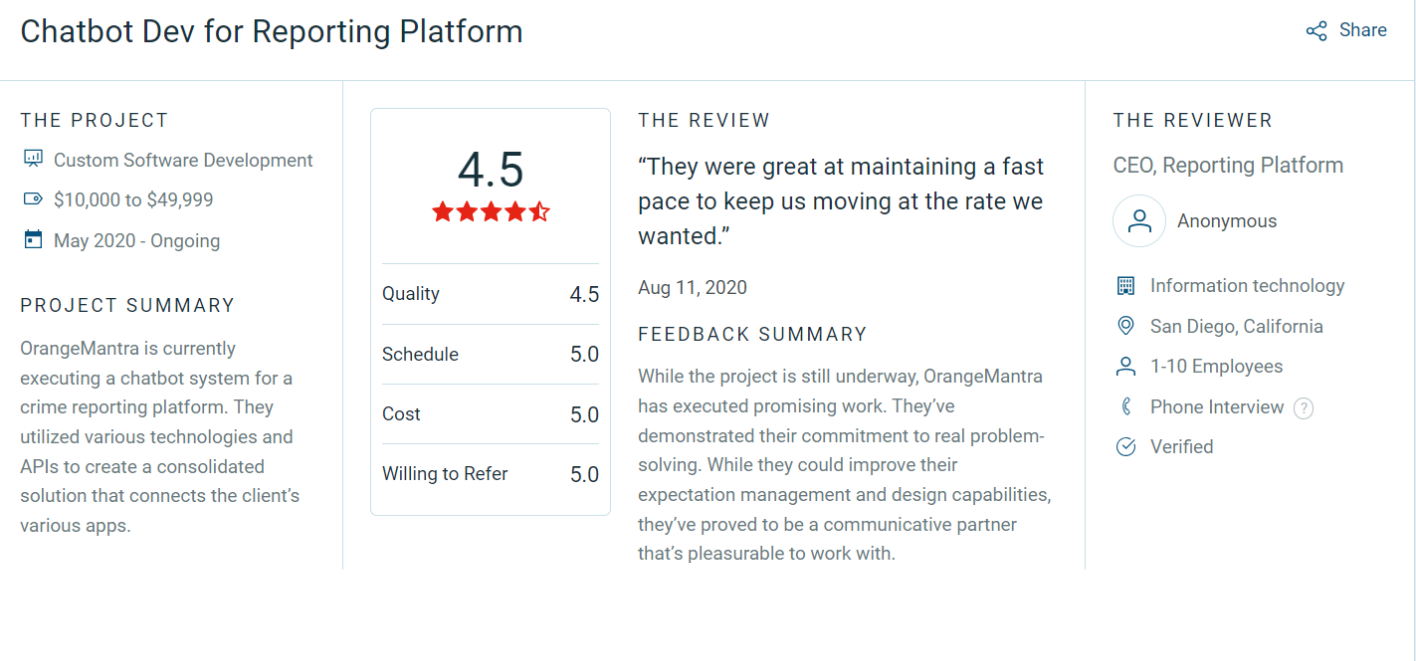
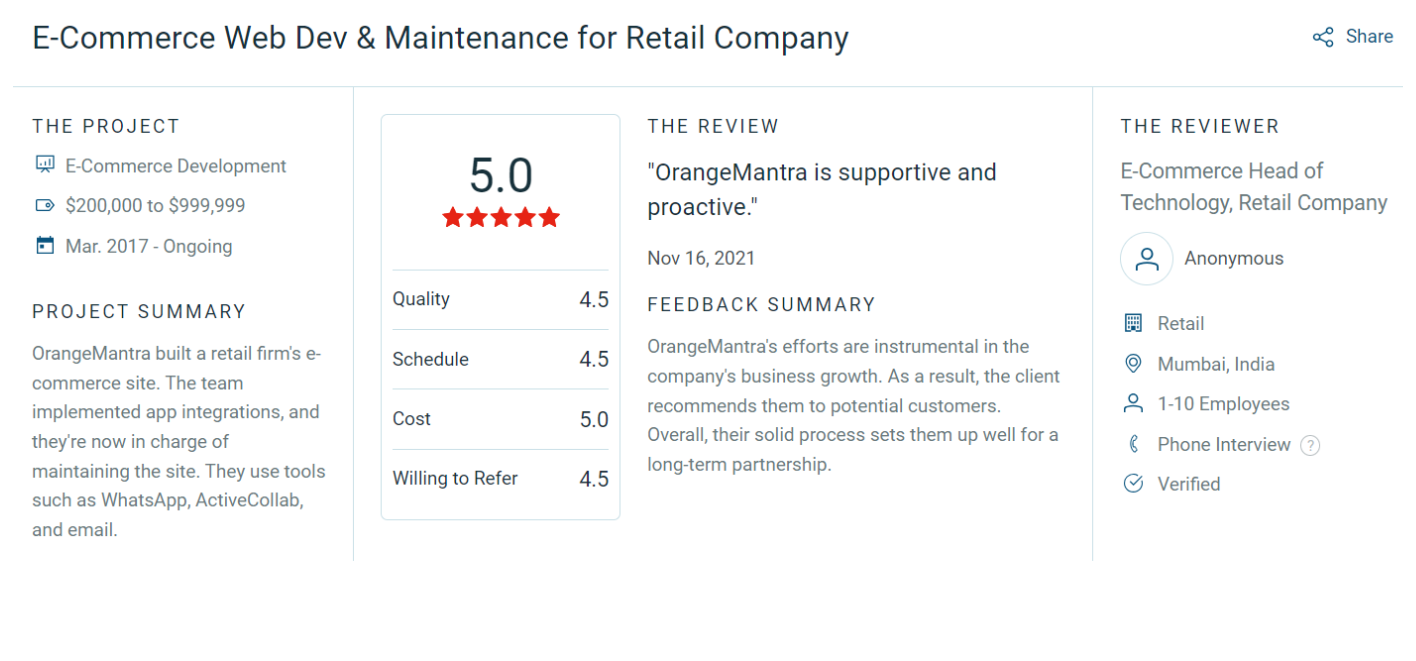
The precision and reliability of data pipelines demands genuine expertise. OrangeMantra has a track record of delivering enterprise-grade ETL development services that organizations trust with their most critical data.
Not Sure Where to Start with Your Data Integration?
We'll help you identify the right ETL approach, build a proof-of-concept pipeline, and scale it into a production-grade data infrastructure — with measurable ROI at every stage.






