

Retail personalization is one of those subjects where everyone agrees it matters, most teams have tried something, and very few are genuinely satisfied with where they have ended up.
The gap between what personalization is supposed to do and what it actually delivers in practice is real, and I have spent a fair amount of time trying to understand why it exists.
Having worked inside these projects, not just advising from the outside but actually building recommendation engines, wiring up customer data platforms, and sitting with the messy reality of retail data in India, I have developed strong views on where things go wrong and what actually moves the needle.
This is my attempt to write that down clearly, including the parts that are less flattering about how the industry approaches this problem.
One thing worth saying at the outset: AI personalization is not a silver bullet. There are trade-offs, and there will be things you have to give up or defer.
But most of the difficulties I see teams running into are avoidable. They come from getting the sequencing wrong or skipping a foundational step in the interest of speed, not from the technology itself being inadequate.
Table of Contents
Why Most Retail Personalization Strategies Fail Before They Start
If there is one thing I would point to as the root cause of underperforming personalization programs, it is fragmented customer data.
Purchase history sits in one system. Browse behaviour lives in another. Loyalty card swipes are in a third. In-store transactions are in a spreadsheet somewhere, updated once a week if you are lucky.
Nobody told these systems to share a common understanding of who the customer actually is, and for years that did not matter. It starts to matter the moment you try to build something intelligent on top of them.
The practical effect is significant. A customer who has been buying from a retailer for three years, spending real money, primarily through in-store visits, can walk onto the website and be treated as a complete stranger because the online and offline customer records have never been reconciled.
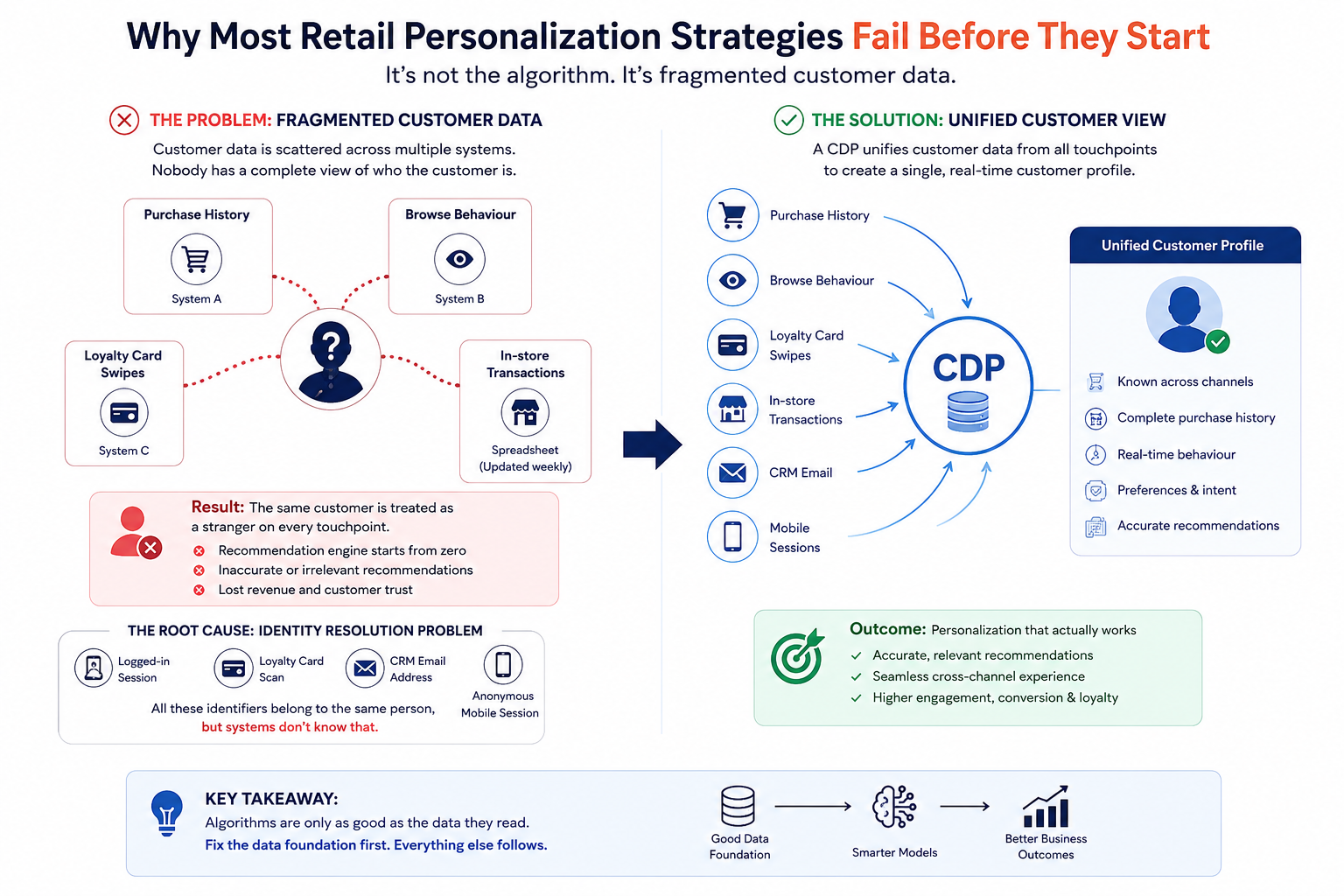
The AI-powered recommendation engine starts from zero, every single session. Whatever it surfaces is essentially an informed guess based on a partial picture.
This is what is known as an identity resolution problem. It involves matching a single customer across every touchpoint they use, whether that is a logged-in session, a loyalty card scan, a CRM email address, or an anonymous browsing session on mobile.
A Customer Data Platform (CDP) with both deterministic matching for known identifiers and probabilistic matching for anonymous sessions is what makes unified customer profiles possible at scale.
The reason I am starting here is that most personalization discussions skip straight to the algorithm, the recommendation logic, the machine learning models. Those things matter, but they are only as good as the customer profiles they read.
I have seen expensive models produce genuinely poor recommendations because the profiles they were working from were incomplete or duplicated across systems. Fix the data foundation first. Everything else follows from that.
How AI Recommendation Engines Actually Drive Revenue in Retail
The most important thing I have learned about recommendation engines, after working on a dozen of them, is that the model architecture is rarely what determines whether the project succeeds.
On a fashion retail project for a Dutch brand, the client saw repeat purchase rate climb 22 percent and average order value improve 14 percent within four months of deployment. Those are solid numbers.
But the thing that drove them was not anything exotic in the underlying algorithm. It was a single behavioural distinction we built into the model, the difference between a gift-buying session and a personal shopping session.
The SaaS recommendation tool the client had been using previously made no such distinction, which meant that when a woman who normally bought structured workwear came to the site looking for a birthday gift for her husband, the engine kept surfacing blazers and office separates.
She ignored every recommendation because none of it was relevant to what she was doing that day. The model was reading her identity correctly but reading her intent completely wrong.
A well-built retail recommendation engine with the help of AI development services also needs to handle returns history properly. If a customer has flagged specific fit issues across multiple returns, the model should learn to deprioritise those product attributes in future recommendations for that individual.
It should distinguish between customers who are browsing and customers who are close to purchasing. It should handle the cold-start problem for new users through content-based filtering on product attributes, building up to collaborative filtering as behavioural data accumulates.
And it needs a retraining schedule, because a model trained on pre-Diwali purchase patterns will be serving the wrong recommendations by February if it has not been updated. That kind of drift is gradual and easy to misattribute to seasonality rather than model staleness.
Why Individual-Level AI Personalization Outperforms Segment-Based Targeting
For a long time I thought getting the customer segments right was most of the job. Urban women, 25 to 34, high purchase frequency. Build the right segments and the rest follows.
A grocery project a couple of years ago changed my thinking on that.
Two customers with an identical demographic profile. Same age bracket, same city, same loyalty tier. One was a new parent, navigating baby formula and infant care products for the first time.
The other was a bachelor training for a marathon, buying protein supplements and oats on a fairly precise weekly cycle. Same segment on paper. Completely different weekly baskets, completely different content that was relevant to them, and completely different things that would have earned their attention.
The personalization system that spoke to both of them through the same lens was failing both of them, quietly, every session. The homepage felt vaguely impersonal to each of them in ways they probably could not articulate.
Segment-based targeting has a real ceiling. It is better than no personalization at all, and for certain channels it remains a practical starting point. But the ceiling becomes visible fairly quickly once you start looking at individual customer behaviour in detail. Two customers who fall into the same demographic segment can have behavioural fingerprints that are almost nothing alike.
Individual-level AI personalization builds a distinct model for each customer and updates it continuously with each new session. The system learns from browse patterns, purchase frequency, search queries, dwell time, add-to-cart-and-remove behaviour, and returns history.
Two customers in the same segment see entirely different recommendation sets, homepage rankings, and promotional content based on what they have individually demonstrated they respond to.
McKinsey’s research puts the revenue difference between segment-level and individual-level personalization at around 10 to 15 percent higher revenue per visitor, which over a full customer base compounds into a meaningful number.
Real-Time Personalization vs Batch Processing: What the Difference Actually Looks Like
There is a detail that comes up in almost every project I work on that sounds like a technical footnote but turns out to matter more than most teams expect.
If a customer completes a purchase and then, for the next 12 hours, sees that same product recommended across every surface of the site, something in the system is fundamentally out of sync. The customer does not usually file a complaint about this. They just lose confidence in the recommendation surface and eventually stop engaging with it.
The cause is almost always batch processing. Systems that refresh customer profiles on an overnight schedule are working from yesterday’s data when they serve today’s recommendations. The purchase that just happened, the wishlist item added ten minutes ago, the search query typed three times in the same session pointing to clear category intent, none of that is reflected in the model until the next batch cycle runs.
Real-time event pipelines change the experience in a way that customers feel even if they cannot describe it. When a customer completes a purchase, the profile updates within milliseconds. The next page load reflects the current customer. Repeated search queries within a session update the homepage ranking before the customer leaves.
Batch processing is not always avoidable, especially early in a personalization program. But moving toward real-time data pipelines as the program matures is what separates personalization that feels genuinely responsive from personalization that feels perpetually one step behind.
Building a First-Party Data Foundation for Retail AI Personalization
Third-party cookies are gone, and the data brokers and ad platforms that once let retailers purchase behavioural profiles of customers they had never directly interacted with are no longer available in the same form. What replaces them is first-party data, the behavioural and transactional signals customers generate through direct engagement with your brand.
Most retailers already have more usable first-party data than they realise. Browse sessions, purchase history, search queries, app interactions, and loyalty card records are all first-party assets. The problem is that they sit in separate systems with no unified customer identity connecting them, which is the same foundational issue I described at the outset.
Beyond connecting existing data, zero-party data adds a cleaner and more intentional layer. This is information customers choose to share directly: size preferences, style preferences, dietary restrictions, gifting occasions, price range.
A customer who tells you they are a size 10 and prefer minimal design has given you more actionable and more reliable information than anything you could infer from browse behaviour. Preference centres built into onboarding flows and post-purchase sequences are a practical way to collect this at scale, with explicit consent, in a way that customers actually appreciate because they see the personalisation it enables.
The retailers who will pull ahead on personalization over the next three years are not necessarily the ones with the most sophisticated models. They are the ones with the cleanest, most complete first-party data assets and a clear understanding of how to use them responsibly.
How to Sequence Your Retail Personalization Strategy for Maximum ROI
The most common sequencing mistake I see is teams trying to launch omnichannel personalization across every surface simultaneously, before any of their models have enough signal to perform reliably.
The result is expensive infrastructure producing mediocre recommendations in six places instead of genuinely useful ones in one.
Starting with email is almost always the right call. Customer identity is already resolved. You are not serving recommendations under millisecond page-load latency pressure. The feedback loop is fast and interpretable.
The model trains on clean, attributable signal. Once email recommendations are working well, the profile data and model logic transfer directly to the homepage, which benefits from already-trained customer profiles rather than starting cold.
How to use computer vision for understanding in-store customer behavior?
In-store integration through computer vision and loyalty app triggers comes later, after the digital foundation is solid.
When it works well, it allows a customer who enters a specific zone in a physical store to receive a contextually relevant in-app notification based on their purchase history and the category they are standing in front of.
The computer vision system identifies the zone, the CDP matches the loyalty ID to the session, and the notification fires within seconds. It is an elegant experience when the underlying data is clean. When it is not, the notification fires with the wrong content and the customer notices immediately.
Build vs Buy vs Partner
On the question of whether to build, buy, or partner: SaaS personalization tools work well for standard catalogs with under five thousand SKUs and relatively uniform product taxonomy.
Custom builds are less often a model problem and more often a data engineering problem. Getting clean, unified, real-time behavioural data into a consumable format is where most custom implementations stall.
For retailers with complex catalogs and multi-channel ambitions, a specialist partnership with an AI-powered ecommerce development company delivers the best outcome because you get models trained on your actual customer data without needing to build an internal machine learning function from scratch.
Common AI Personalization Mistakes Retailers Need to Stop Making
Here are the 4 mistakes in AI retail personalization, you should avoid from now onwards.

-
Deploying before the data volume is there.
Collaborative filtering needs roughly 10,000 to 50,000 product interaction events before it produces reliable output. Launching before that threshold means the model has too little signal to work from and the recommendations it surfaces are effectively undifferentiated.
Customers who experience irrelevant recommendations in early sessions tend to dismiss that surface permanently, even after the model improves. Content-based filtering on product attributes is a solid bridge while behavioural data accumulates.
-
Treating the model as a finished product.
A recommendation model trained on November’s pre-festive purchase patterns will be serving the wrong content by February if it has not been retrained. The drift is gradual and easy to misread as seasonal underperformance rather than model staleness.
Quarterly retraining should be a baseline, with monitoring thresholds that trigger a review when recommendation click-through drops below a defined level for two consecutive weeks.
-
Measuring without a control group.
The most common measurement mistake is comparing before-and-after metrics across the whole customer base. Seasonal shifts, new product launches, and market changes all influence those numbers independently of the personalization program.
The only measurement that isolates the actual contribution of personalization is a held-out control group receiving no personalised treatment. The lift between the two groups is the real number.
-
Skipping identity resolution.
Worth repeating because it surfaces on nearly every project. If customer records are fragmented across systems, the model works with a partial picture of each person it tries to serve.
The personalization layer is only as good as the profiles it reads. Fixing identity resolution before building on top of it is not optional.
FAQs
Does AI personalization actually work for mid-size retailers or is it mainly for enterprise brands?
It works at mid-size scale. The deployment cost for a solid recommendation engine on Shopify or Magento has come down considerably over the past few years. The larger investment is typically the data infrastructure, connecting customer identity across channels and consolidating behavioural data into a unified profile store. Once that foundation exists, the personalization layer is the more straightforward part of the build.
How long before we can expect to see measurable results?
On a well-implemented project with clean underlying data, early signals like recommendation click-through rate and session depth typically appear within four to six weeks of go-live. Revenue metrics worth standing behind, average order value lift and repeat purchase rate, become measurable at around three months. The full picture usually lands within six months. If the data infrastructure needs significant work before the model can be built, add six to eight weeks at the front end. Skipping that to hit an earlier launch date costs more to fix later than it would have cost to do it properly at the start.
What is the single most important thing a retailer should do before starting a personalization program?
Consolidate your customer identity. Before any recommendation logic, before any model training, before any integration work: can you look up one customer and see their complete journey across every touchpoint? If the answer is no, that is the starting point. Everything built on top of fragmented customer data will underperform in proportion to how fragmented it is.




